(14)地理营销
本文由SCY翻译自《Geocomputation with R》第十四章
- T本章要求使用下列包 (tmaptools 必须安装):
1 | library(sf) |
- 必要的数据将会在适当的时候下载。
为了方便读者并确保易于复现,我们已将下载的数据放在 spDataLarge 包中供使用。
引言
本章展示了在第一部分和第二部分学到的技能如何应用于特定领域:地理营销(有时也称为位置分析或位置智能)。这是一个广泛的研究和商业应用领域。地理营销的典型例子是如何选择一个新店的位置。这里的目标是吸引最多的顾客,最终实现最大的利润。此外,还有许多非商业应用可以利用这种技术来造福公众,例如选择新的卫生服务设施的位置。
人类对于位置分析来说是基本要素,特别是人们可能会在哪里花费时间和其他资源。有趣的是,生态学的概念和模型与用于店铺选址分析的概念和模型非常相似。动植物可以在某些“最优”位置最好地满足其需求,这些位置是基于随空间变化的变量确定的。这是地理计算和地理信息科学的一个重要优势:概念和方法可以转移到其他领域。例如,北极熊更喜欢气温较低且食物(海豹和海狮)丰富的北纬地区。同样地,人类倾向于聚集在某些地方,创造出类似于北极地区的生态位的经济位。位置分析的主要任务是基于现有数据找出这些特定服务的“最优位置”在哪里。典型的研究问题包括:
- 目标群体居住在哪里,他们经常去哪些地区?
- 竞争的商店或服务位于哪里?
- 有多少人可以轻松到达特定的商店?
- 现有的服务是否过度或不足地利用了市场潜力?
- 公司在特定地区的市场份额是多少?
本章通过一个基于实际数据的假设案例研究,演示了地理计算如何回答这些问题。
案例研究:德国自行车商店
假设您正在德国开设一家自行车连锁店。这些店铺应该位于尽可能多的潜在顾客所在的城市地区。此外,一个虚构的调查(仅用于本章,非商业用途!)表明,单身年轻男性(年龄在20到40岁之间)最有可能购买您的产品:这就是目标受众。幸运的是,您有足够的资本来开设多家店铺。但是,它们应该放在哪里呢?咨询公司(雇佣地理营销分析师的公司)通常会收取高额费用来回答此类问题。幸运的是,借助开放数据和开源软件,我们可以自己解决这些问题。以下几节将演示如何将本书前几章学到的技术应用于执行服务位置分析中的常见步骤:
- 整理来自德国人口普查的输入数据
- 将表格化的人口普查数据转换为栅格对象
- 识别人口密度较高的大都市地区
- 为这些地区下载详细的地理数据(使用osmdata从OpenStreetMap下载)
- 使用地图代数创建评分栅格,以评估不同位置的相对吸引力
尽管我们将这些步骤应用于一个特定的案例研究,但它们可以推广到许多店铺选址或公共服务提供的情景。
整理数据
德国政府提供了分辨率为1公里或100米的栅格化人口普查数据。下面的代码块用于下载、解压缩和读取1公里分辨率的数据。
1 | download.file("https://tinyurl.com/ybtpkwxz", |
请注意,census_de 数据也可以从 spDataLarge 包中获取:
1 | data("census_de", package = "spDataLarge") |
census_de 对象是一个包含13个变量的数据框,涵盖德国境内超过360,000个栅格单元。对于我们的工作,我们只需要其中的一个子集:东向坐标 (x)、北向坐标 (y)、居民数量(人口;pop)、平均年龄(mean_age)、女性比例(women)和平均家庭规模(hh_size)。下面的代码块从这些变量中选择并将其从德文重命名为英文,并在表格 @ref(tab:census-desc) 中进行了总结。此外,mutate() 函数被用于将值-1和-9(表示“未知”)转换为 NA。
1 | # pop = population, hh_size = household size |
Table: Categories for each variable in census data from Datensatzbeschreibung…xlsx located in the downloaded file census.zip (see Figure @ref(fig:census-stack) for their spatial distribution).
| Class | Population | % female | Mean age | Household size |
|---|---|---|---|---|
| 1 | 3-250 | 0-40 | 0-40 | 1-2 |
| 2 | 250-500 | 40-47 | 40-42 | 2-2.5 |
| 3 | 500-2000 | 47-53 | 42-44 | 2.5-3 |
| 4 | 2000-4000 | 53-60 | 44-47 | 3-3.5 |
| 5 | 4000-8000 | >60 | >47 | >3.5 |
| 6 | >8000 |
创建人口普查栅格
在预处理之后,可以使用rast()函数将数据转换为SpatRaster对象。当将其 type 参数设置为 xyz 时,输入数据框的 x 和 y 列应该对应于正规栅格上的坐标。所有其余列(在这里是 pop、women、mean_age、hh_size)将用作栅格图层的值(请参阅图 @ref(fig:census-stack);还可以在我们的 GitHub 存储库中的code/14-location-figures.R 文件中找到相关代码)。
1 | input_ras = terra::rast(input_tidy, type = "xyz", crs = "EPSG:3035") |
1 | input_ras |
📌请注意,我们使用的是等面积投影(EPSG:3035;欧洲兰伯特等面积投影),即每个栅格单元的面积相同,这里是1000 x 1000平方米。由于我们主要使用诸如每个栅格单元的居民数量或女性比例等密度数据,因此每个栅格单元的面积相同非常重要,以避免“苹果与橙子比较”。请注意,在地理坐标系(CRS)中,栅格单元的面积在向极地方向不断减小,因此需要谨慎处理。
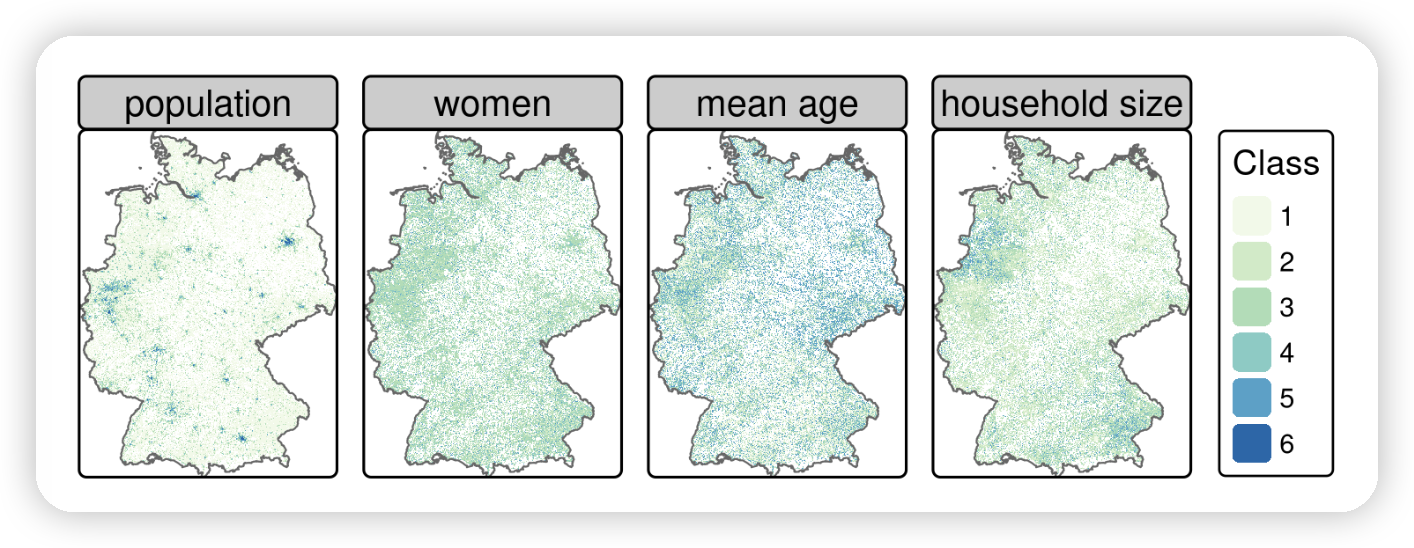
Gridded German census data of 2011 (see Table @ref(tab:census-desc) for a description of the classes).
下一步是根据前面章节提到的调查,使用 terra 函数 classify() 对存储在 input_ras 中的栅格图层的值进行重新分类。对于人口数据,我们使用类均值将类别转换为数值数据类型。假设栅格单元的值为1(‘class 1’ 中的单元包含3到250名居民),则栅格单元的人口被假定为127;如果值为2(包含250到500名居民的单元),则人口被假定为375,依此类推(请参阅上表)。对于’类别6’,栅格单元的值被选为8000名居民,因为这些单元包含的人口超过8000人。当然,这些都是对真实人口的近似值,而不是精确值。^[在这个重新分类阶段引入的潜在误差将在练习中进行探讨。]然而,这个详细级别足以划定大都市区域(请参阅下一节)。
与变量 pop 不同,该变量表示总人口的绝对估计,其他变量被重新分类为与调查中使用的权重相对应的权重。例如,变量 women 中的’类别1’代表的是人口中女性占0到40%的地区;这些地区被重新分类为较高的权重3,因为目标人群主要是男性。同样地,包含最年轻人口和最高比例的单身家庭的类别被重新分类为高权重。
1 | rcl_pop = matrix(c(1, 1, 127, 2, 2, 375, 3, 3, 1250, |
请注意,我们确保了列表中重新分类矩阵的顺序与 input_ras 的元素顺序相同。例如,第一个元素在两种情况下都对应于人口。随后,for 循环\index{loop!for} 将重新分类矩阵应用于相应的栅格图层。最后,下面的代码块确保 reclass 图层与 input_ras 的图层具有相同的名称。
1 | reclass = input_ras |
1 | reclass |
定义都市区
我们特意将大都市区域定义为面积为20平方公里且居住人口超过500,000人的像素。在这种粗分辨率下,可以通过使用 aggregate()快速创建像素。下面的命令使用参数 fact = 20 将结果的分辨率降低了20倍(回想一下,原始栅格的分辨率是1平方公里):
1 | pop_agg = terra::aggregate(reclass$pop, fact = 20, fun = sum, na.rm = TRUE) |
接下来的步骤是仅保留居住人口超过500,000人的单元格。您可以使用以下代码来实现:
1 | pop_agg = pop_agg[pop_agg > 500000, drop = FALSE] |
绘制这些数据将显示出八个大都市区域。每个区域由一个或多个栅格单元组成。如果我们能够将属于同一区域的所有单元格连接起来,那将会很好。terra 的 patches() 命令正是这样的功能。随后,as.polygons() 将栅格对象转换为空间多边形,而 st_as_sf() 将其转换为 sf 对象。
1 | metros = pop_agg |> |

The aggregated population raster (resolution: 20 km) with the identified metropolitan areas (golden polygons) and the corresponding names.
生成的八个适合自行车店的大都市区域;请参阅 code/14-location-figures.R 以创建图表)仍然缺少名称。逆地理编码方法可以解决这个问题:根据坐标找到对应的地址。因此,提取每个大都市区域的中心坐标可以作为逆地理编码API的输入。这正是 tmaptools 包中的 rev_geocode_OSM() 函数所期望的。此外,将 as.data.frame 设置为 TRUE 将返回一个包含多列关于位置的 data.frame,包括街道名称、门牌号和城市。然而,在这里,我们只关注城市的名称。
1 | metro_names = sf::st_centroid(metros, of_largest_polygon = TRUE) |> |
为了确保读者使用完全相同的结果,我们已将它们存储在 spDataLarge 中,对象名称为 metro_names。
Table: Result of the reverse geocoding.
| city | state |
|---|---|
| Hamburg | NA |
| Berlin | NA |
| Velbert | Nordrhein-Westfalen |
| Leipzig | Sachsen |
| Frankfurt am Main | Hessen |
| Nürnberg | Bayern |
| Stuttgart | Baden-Württemberg |
| München | Bayern |
总体而言,我们对 city 列作为大都市名称(上表)感到满意,除了一个例外,即属于杜塞尔多夫大区的费尔伯特。因此,我们将 Velbert 替换为 Düsseldorf(上图)。像 ü 这样的特殊字符可能会在后续的操作中引起问题,例如在使用 opq() 确定大都市区域的边界框时(请参见下面的内容),因此我们避免使用它们。
1 | metro_names = metro_names$city |> |
兴趣点
osmdata包提供了易于使用的访问OSM数据的方法。我们不是下载整个德国的商店数据,而是将查询限制在了定义好的大都市区域,以减少计算负担并且只获取感兴趣区域内的商店位置。下面的代码块使用了许多函数,包括:
map()(tidyverse 中的lapply()等效函数),它遍历了八个大都市名称,随后在OSM\index{OpenStreetMap}查询函数opq()中定义了边界框。add_osm_feature()用于指定带有键值为shop的OSM元素(请参阅 wiki.openstreetmap.org 以获取常见的键值对列表)。osmdata_sf()将OSM数据转换为空间对象(sf类)。while(),如果第一次下载失败,将重复尝试(在本例中为三次)。^[有时在第一次尝试下载OSM数据时可能会失败。]
在运行此代码之前,请考虑它将下载近2GB的数据。为了节省时间和资源,我们已将名为 shops 的输出放入 spDataLarge 包中。要在您的环境中使用它,请运行 data("shops", package = "spDataLarge")。
1 | shops = purrr::map(metro_names, function(x) { |
在我们定义的任何大都市区域中几乎不可能没有商店。以下的 if 条件仅仅检查每个区域是否至少有一家商店。如果没有的话,我们建议尝试再次为该/这些特定区域下载商店数据。
1 | # checking if we have downloaded shops for each metropolitan area |
为确保每个列表元素(一个 sf 数据框)具有相同的列^[这并不是一定的,因为OSM的贡献者在收集数据时并不总是一样仔细。],我们只保留 osm_id 和 shop 列,使用 map_dfr 循环将所有商店合并为一个大的 sf 对象。
1 | # select only specific columns |
注意:shops 已经在 spDataLarge 中提供,并且可以通过以下方式访问:
1 | data("shops", package = "spDataLarge") |
唯一剩下的任务是将空间点对象转换为栅格。sf 对象 shops 将被转换为一个栅格,其参数(维度、分辨率、CRS)与 reclass 对象相同。重要的是,在此处使用 length() 函数来计算每个单元格中的商店数量。
因此,下面的代码块的结果是商店密度的估计(商店/平方公里)。在使用 rasterize() 之前,使用 st_transform() 来确保两个输入的CRS匹配。
1 | shops = sf::st_transform(shops, st_crs(reclass)) |
与其他栅格图层(人口、女性、平均年龄、户籍人口)一样,poi 栅格也被重新分类为四个类别。在一定程度上,定义类别间隔是一个主观的任务。可以使用等距断点、分位数断点、固定值或其他方法。在这里,我们选择了费舍尔-詹金斯自然断点法,该方法最小化了类内方差,其结果为重新分类矩阵提供了一个输入。
1 | # construct reclassification matrix |
明确合适的位置
在将所有图层组合在一起之前,只剩下几个步骤:将 poi 添加到 reclass 栅格堆叠中,并将人口图层从中移除。后者的原因有两点。首先,我们已经勾勒出了大都市区域,即人口密度高于德国其他地区平均水平的地区。其次,虽然在特定的服务区域内有许多潜在的顾客可能是有优势的,但仅仅数量本身可能并不真正代表所需的目标群体。例如,高层住宅区是人口密度较高的地区,但不一定具有购买昂贵自行车配件的高购买力。
1 | # remove population raster and add poi raster |
与其他数据科学项目一样,数据检索和“整理”在整个工作量中占据了很大一部分。有了干净的数据,最后一步——通过将所有栅格图层相加来计算最终得分——可以在一行代码中完成。
1 | # calculate the total score |
例如,得分大于9的分数可能是一个适当的阈值,表示可以放置自行车店的栅格单元格;请参阅 code/14-location-figures.R)。
1 | #> The legacy packages maptools, rgdal, and rgeos, underpinning the sp package, |
1 | <div class="leaflet html-widget html-fill-item-overflow-hidden html-fill-item" id="htmlwidget-841de324d41155df19a0" style="width:100%;height:415.296px;"></div> |
Suitable areas (i.e., raster cells with a score > 9) in accordance with our hypothetical survey for bike stores in Berlin.
讨论和下一步
所呈现的方法是GIS的典型应用示例。我们将调查数据与基于专家知识和假设的方法相结合(定义大都市区域,定义类别间隔,定义最终得分阈值)。这种方法不如应用分析适用于科学研究,因为它可以提供基于证据的适合自行车店的区域,应该与其他信息来源进行比较。对方法的一些变更可以改进分析:
- 在计算最终得分时,我们使用了相等的权重,但其他因素,如户籍人口,可能与女性比例或平均年龄一样重要。
- 我们使用了所有兴趣点,但只有与自行车店相关的兴趣点,如自行车店、五金店、自行车、钓鱼、狩猎、摩托车、户外和运动用品店(请参阅 OSM Wiki 上可用的店铺值范围)可能会产生更精细的结果。
- 更高分辨率的数据可能会改善输出(请参阅练习)。
- 我们仅使用了有限的变量集和来自其他来源的数据,如 INSPIRE geoportal 或来自 OpenStreetMap 的自行车路径数据,可以丰富分析。
- 未考虑交互作用,如男性比例和单身户之间可能存在的关系。
简而言之,分析可以在多个方向上进行扩展。然而,它应该给您对如何在geomarketing背景下在R中获取和处理空间数据的第一印象和理解。
最后,我们必须指出,所呈现的分析仅仅是找到合适位置的第一步。到目前为止,我们已经确定了大小为1x1公里的区域,代表根据我们的调查可能适合自行车店的位置。分析的后续步骤可以是:
- 基于特定服务区域内的居民数量找到最佳位置。例如,在骑自行车的15分钟行程范围内,店铺应该为尽可能多的人提供可达性(服务区域路由)。在此过程中,我们应该考虑到远离店铺的人越远,他们实际访问店铺的可能性就越小(距离衰减函数)。
- 此外,考虑竞争对手也是一个好主意。也就是说,如果已经有一家自行车店在所选位置附近,可能的顾客(或销售潜力)应该在竞争对手之间分配。
- 我们需要找到适合并且价格合理的房地产,例如在可访问性、停车位的可用性、过路人的期望频率、有大窗户等方面。
练习
E1. 首先,您需要从提供的链接下载包含居民信息的CSV文件(以100米单元格分辨率)。请注意,解压缩后的文件大小为1.23 GB。您可以使用readr::read_csv将其读入R中。在具有16 GB RAM的机器上,这需要30秒钟。data.table::fread()可能会更快,它返回一个data.table()类的对象。使用dplyr::as_tibble()将其转换为tibble。构建一个居民栅格,将其聚合到1 km的单元格分辨率,并将其与我们使用类平均值创建的居民栅格(inh)进行比较。
E2. 假设我们的自行车店主要向老年人销售电动自行车。相应地更改年龄栅格,重复剩余的分析,并将更改与我们的原始结果进行比较。