(12)统计学习
本文由SCY翻译自《Geocomputation with R》第十二章
前提条件
本章假设您已经具备地理数据分析的熟练技能,例如通过学习并完成章节空间数据至地理数据重投影中的练习来获得。强烈推荐熟悉广义线性模型(GLM)和机器学习。
本章使用以下的R包:^[虽然不需要附加,但还必须安装GGally、lgr、kernlab、mlr3measures、paradox、pROC、progressr 和 spDataLarge包。]
1 | library(sf) |
当然,所需数据将在适当的时候附上。
引言
统计学习主要关注使用统计和计算模型来识别数据中的模式,并根据这些模式进行预测。由于其起源,统计学习是 R 语言的一大优势(见章节地理计算软件)。^[几十年来,将统计技术应用于地理数据一直是地统计学、空间统计学和点模式分析领域中的一个活跃的研究课题。统计学习结合了统计和机器学习的方法,并可分为监督和无监督技术。这两者越来越多地应用于从物理学、生物学和生态学到地理学和经济学等各个学科]。
本章重点介绍有训练数据集的监督技术,而非像聚类这样的无监督技术。响应变量可以是二元的(如山体滑坡发生与否)、分类的(土地利用)、整数(物种丰富度计数)或数值的(以 pH 衡量的土壤酸度)。监督技术用于建模——响应与一个或多个预测变量之间的关系——这些响应是基于一组观测样本而已知的。
大多数机器学习研究的主要目的是进行良好的预测。机器学习在“大数据”时代蓬勃发展,因为其方法对输入变量几乎没有假设,并且能处理巨大的数据集。机器学习适用于预测未来客户行为、推荐服务(音乐、电影、接下来购买什么)、面部识别、自动驾驶、文本分类和预测性维护(基础设施、产业)等任务。
本章基于一个案例研究:(空间)预测山体滑坡。
该应用与定义在引言章中的地理计算的应用性有关,并说明了机器学习在唯一目的是预测时如何借鉴统计学领域。因此,本章首先使用广义线性模型介绍建模和交叉验证的概念。在此基础上,该章实施了一个更典型的机器学习算法,即支持向量机(SVM)。模型的预测性能将使用空间交叉验证(CV)进行评估,该方法考虑到地理数据是特殊的。
CV确定模型泛化到新数据的能力,通过将数据集(反复)分割为训练集和测试集。它使用训练数据来拟合模型,并检查其在对测试数据进行预测时的性能。CV 有助于检测过拟合,因为过于紧密地预测训练数据(噪声)的模型通常会在测试数据上表现不佳。
随机分割空间数据可能导致训练点与测试点在空间上是邻近的。由于空间自相关,在这种情况下,测试数据集和训练数据集将不是独立的,因此交叉验证无法检测出可能的过拟合。空间交叉验证缓解了这个问题,并且是本章的核心主题。
案例: 滑坡敏感性
本案例研究基于南厄瓜多尔滑坡地点的一个数据集,如下图所示,并在@muenchow_geomorphic_2012中详细描述。该论文中使用的数据集的一个子集提供在spDataLarge包中,可以如下加载:
1 | data("lsl", "study_mask", package = "spDataLarge") |
T上面的代码加载了三个对象:一个名为lsl的data.frame,一个名为study_mask的sf对象,以及一个名为ta的SpatRaster,其中包含地形属性栅格。lsl包含一个因子列lslpts,其中TRUE对应于观察到的滑坡’发起点’,坐标存储在列x和y中。^[滑坡发起点位于滑坡多边形的断崖中。有关进一步的详细信息。]
有175个滑坡点和175个非滑坡点,如summary(lsl$lslpts)所示。这175个非滑坡点是从研究区域随机抽样的,但必须落在滑坡多边形周围的小缓冲区之外。
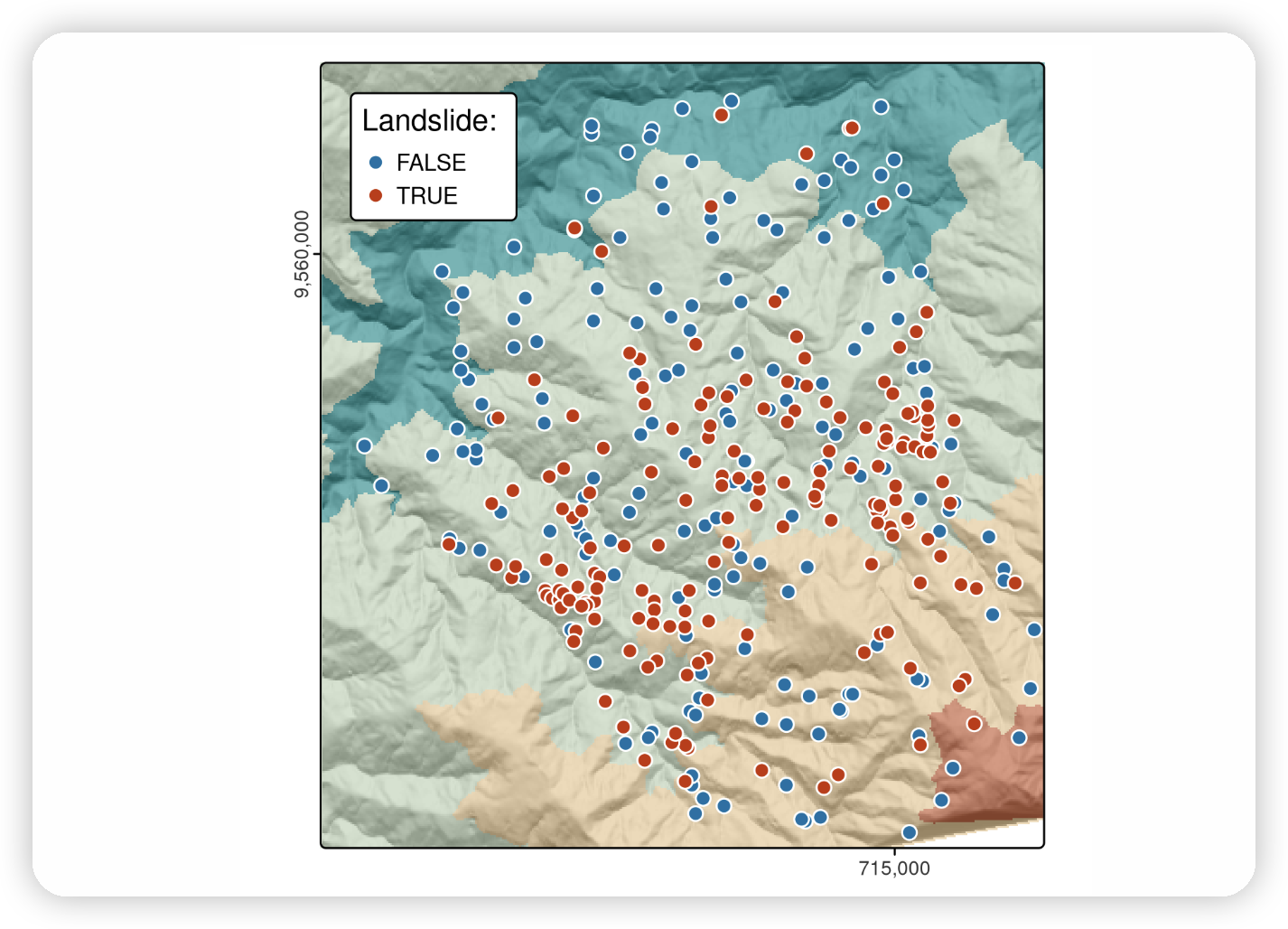
Landslide initiation points (red) and points unaffected by landsliding (blue) in Southern Ecuador.
lsl的前三行,四舍五入为两位有效数字,可以在下表中找到。
| x | y | lslpts | slope | cplan | cprof | elev | log10_carea | |
|---|---|---|---|---|---|---|---|---|
| 1 | 713888 | 9558537 | FALSE | 34 | 0.023 | 0.003 | 2400 | 2.8 |
| 2 | 712788 | 9558917 | FALSE | 39 | -0.039 | -0.017 | 2100 | 4.1 |
| 350 | 713826 | 9559078 | TRUE | 35 | 0.020 | -0.003 | 2400 | 3.2 |
要对滑坡易发性进行建模,我们需要一些预测因子。由于地形属性经常与滑坡有关[@muenchow_geomorphic_2012],我们已经从ta提取到lsl中以下的地形属性:
slope:坡度角(°)cplan:平面曲率(rad m^−1^)表示坡度的汇聚或发散,从而表示水流cprof:剖面曲率(rad m^-1^)作为流速加速的衡量标准,也称为坡度角的下坡变化elev:海拔高度(m a.s.l.)作为研究区不同海拔带植被和降水的表示log10_carea:集水区面积(log10 m^2^)的常用对数,表示流向某个位置的水量
使用R-GIS桥计算地形属性并将其提取到滑坡点(参见本章末尾的练习部分)可能是一个值得尝试的练习。
在R中的传统建模方法
在介绍mlr3包之前,这是一个提供统一接口以访问数十种学习算法的 umbrella 包,值得先看一下R传统的建模接口。这一介绍到有监督的统计学习为进行空间CV提供了基础,并有助于更好地理解随后呈现的mlr3方法。
监督学习涉及将响应变量作为预测因子的函数进行预测。在R中,建模函数通常使用公式来指定(有关R公式的更多详细信息,请参阅?formula)。以下命令指定并运行一个广义线性模型:
1 | fit = glm(lslpts ~ slope + cplan + cprof + elev + log10_carea, |
理解这三个输入参数各自的意义是非常有价值的:
- 一个公式,用于指定由预测因子决定的滑坡发生(
lslpts) - 一个家族(family),用于指定模型的类型,在这个例子中是
binomial,因为响应是二元的(见?family) - 包含响应和预测因子(作为列)的数据框
可以如下打印这个模型的结果(summary(fit)提供了关于结果的更详细的描述):
1 | class(fit) |
模型对象fit,其类别为glm,包含了定义响应和预测因子之间拟合关系的系数。这个对象也可以用于预测。这是通过通用的predict()方法来完成的,在这个案例中,它调用了predict.glm()函数。将type设置为response会返回lsl中每个观测的预测概率(即滑坡发生的概率),如下图所示(见?predict.glm):
1 | pred_glm = predict(object = fit, type = "response") |
通过将系数应用于预测因子的栅格数据,可以创建空间分布图。这可以手动完成,也可以使用terra::predict()来完成。除了一个模型对象(fit)外,这个函数还需要一个具有预测因子(栅格层)的SpatRaster,这些预测因子的名称应与模型输入数据框中的名称相同(见下图)。
1 | # making the prediction |
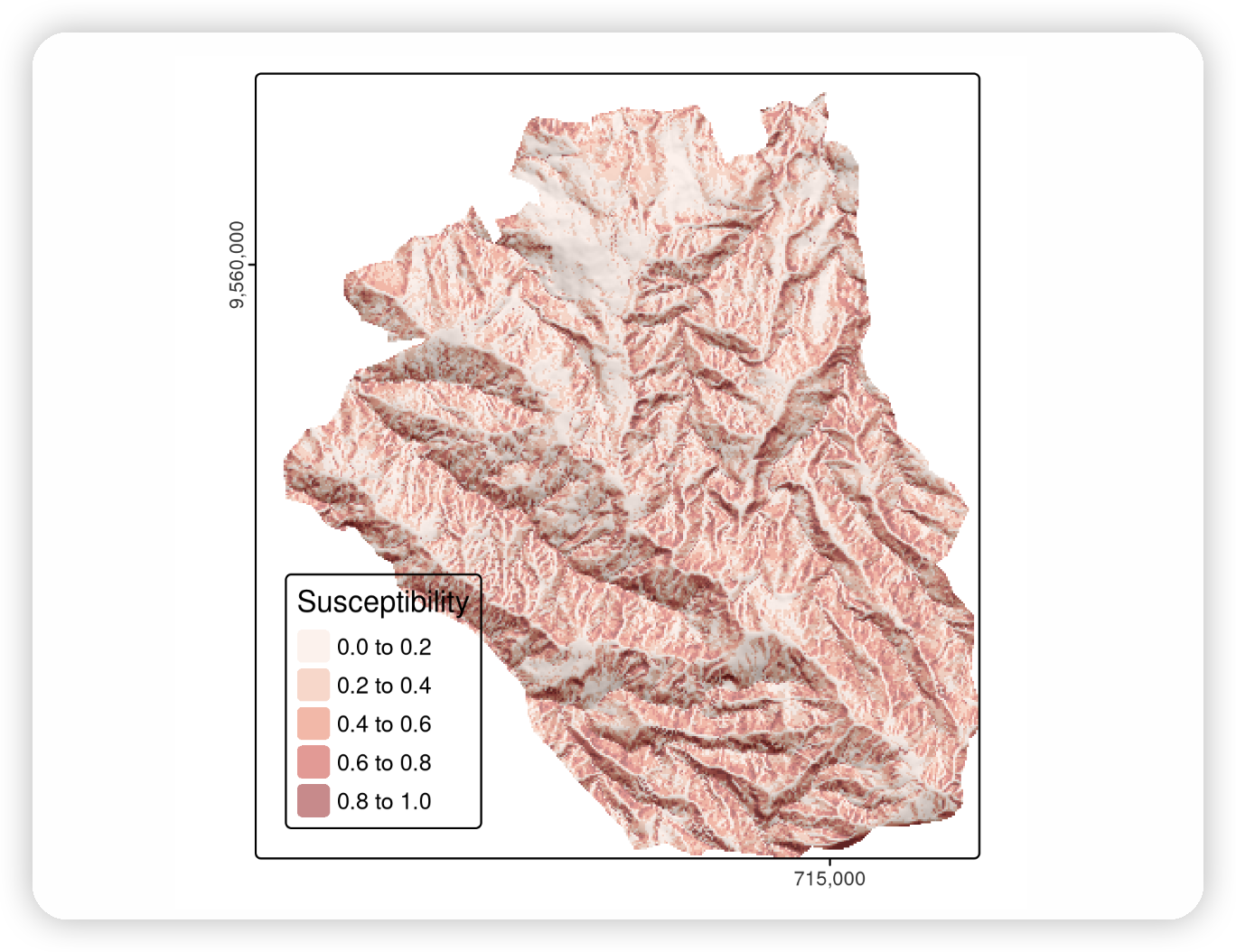
Spatial distribution mapping of landslide susceptibility using a GLM.
在进行预测时,我们忽略了空间自相关,因为我们假设平均预测准确性在有或没有空间自相关结构的情况下保持不变。然而,也可以将空间自相关结构纳入模型和预测中。
尽管这超出了本书的范围,但我们为感兴趣的读者提供了一些查阅的方向:
- 回归克里金(Regression Kriging)的预测结合了回归的预测和回归残差的克里金。
- 人们还可以向广义最小二乘模型[
nlme::gls()]添加空间相关(依赖)结构。 - 人们也可以使用混合效应建模方法。
基本上,随机效应对响应变量施加了依赖结构,从而使某一类的观察结果与另一类的观察结果更相似。类别可以是蜜蜂巢、猫头鹰巢、植被样带或高度分层。这种混合建模方法假设随机截距是正态和独立分布的。这甚至可以通过使用正态和空间依赖的随机截距来扩展。然而,为此,你可能需要采用贝叶斯建模方法,因为频率论软件工具在这方面尤其有限,尤其是对于更复杂的模型。
空间分布图是模型(上图)的一个非常重要的结果。更重要的是,基础模型在制作这些图时有多好,因为如果模型的预测性能差,预测图就毫无用处。评估二项模型预测性能的最流行指标是接收器操作特性曲线下的面积(AUROC)。这是一个介于0.5和1.0之间的值,其中0.5表示模型不比随机模型好,1.0表示两个类的完美预测。因此,AUROC越高,模型的预测能力越好。以下代码块使用roc()计算模型的AUROC值,该函数将响应和预测值作为输入。auc()返回曲线下的面积。
1 | pROC::auc(pROC::roc(lsl$lslpts, fitted(fit))) |
AUROC\index{AUROC} 值为
0.82 代表了一个良好的拟合。然而,这是一个过于乐观的估计,因为我们是在完整数据集上进行的计算。为了得到一个偏差较小的评估,我们需要使用交叉验证,并且在处理空间数据的情况下,应使用空间CV。
介绍(空间)交叉验证
交叉验证属于重采样方法的家族 [@james_introduction_2013]。基本思想是将数据集(反复)分为训练集和测试集,其中训练数据用于拟合模型,然后将该模型应用于测试集。通过使用如二项式案例中的AUROC这样的性能度量,将预测值与测试集中已知的响应值进行比较,从而得到模型将学习到的关系泛化到独立数据的能力的偏差较小的评估。例如,100次重复的5折交叉验证意味着将数据随机分为五个部分(折叠),每个折叠都被用作一次测试集(见下图的上行)。这保证了每个观测值都在测试集中使用一次,并需要拟合五个模型。随后,这一过程重复100次。当然,每次重复中的数据分割都会有所不同。总体而言,这合计为500个模型,而所有模型的平均性能度量(AUROC)即为模型的整体预测能力。
然而,地理数据是特殊的。正如我们将在运输章节中看到的,地理学的“第一定律”指出,彼此靠近的点通常比远离的点更相似 [@miller_tobler_2004]。这意味着这些点在统计上并不独立,因为在传统的CV中,训练点和测试点通常过于靠近(见下图的第一行)。靠近“测试”观测值的“训练”观测值可能提供一种“偷窥预览”:这些信息本应对训练数据集不可用。为了缓解这一问题,“空间划分”被用于将观测值分为空间上不相交的子集(使用观测值的坐标进行k-均值聚类;@brenning_spatial_2012;见下图的第二行)。这种划分策略是空间CV和传统CV之间的唯一差异。因此,空间CV导致了对模型预测性能的偏差较小的评估,从而有助于避免过拟合。
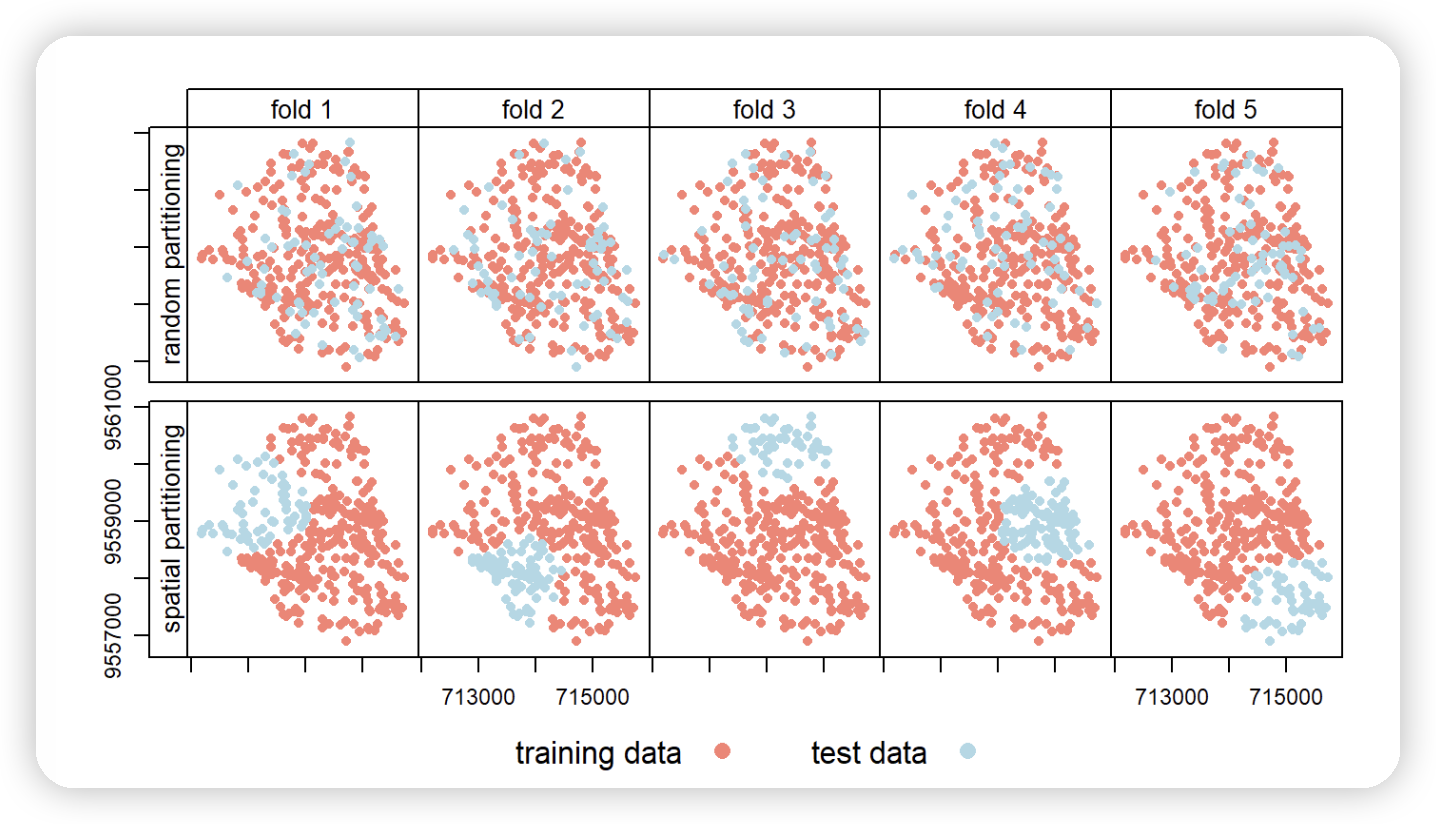
Spatial visualization of selected test and training observations for cross-validation of one repetition. Random (upper row) and spatial partitioning (lower row).
使用mlr3进行空间交叉验证
如CRAN 机器学习任务视图所描述的,有数十个用于统计学的包。熟悉其中每一个包,包括如何进行交叉验证和超参数调整,可能是一个耗时的过程。比较来自不同包的模型结果可能更为繁琐。mlr3 包和生态系统是为了解决这些问题而开发的。它充当一个“元包”,为包括分类、回归、生存分析和聚类在内的流行的有监督和无监督统计学习技术提供统一的接口 [@lang_mlr3_2019; @becker_mlr3_2022]。标准化的 mlr3 接口基于八个“构建块”。
如下图所示,这些构建块有明确的顺序。
(ref:building-blocks) mlr3包的基础构建块。来源:@becker_mlr3_2022。(得到了友好地重新使用此图的许可。)
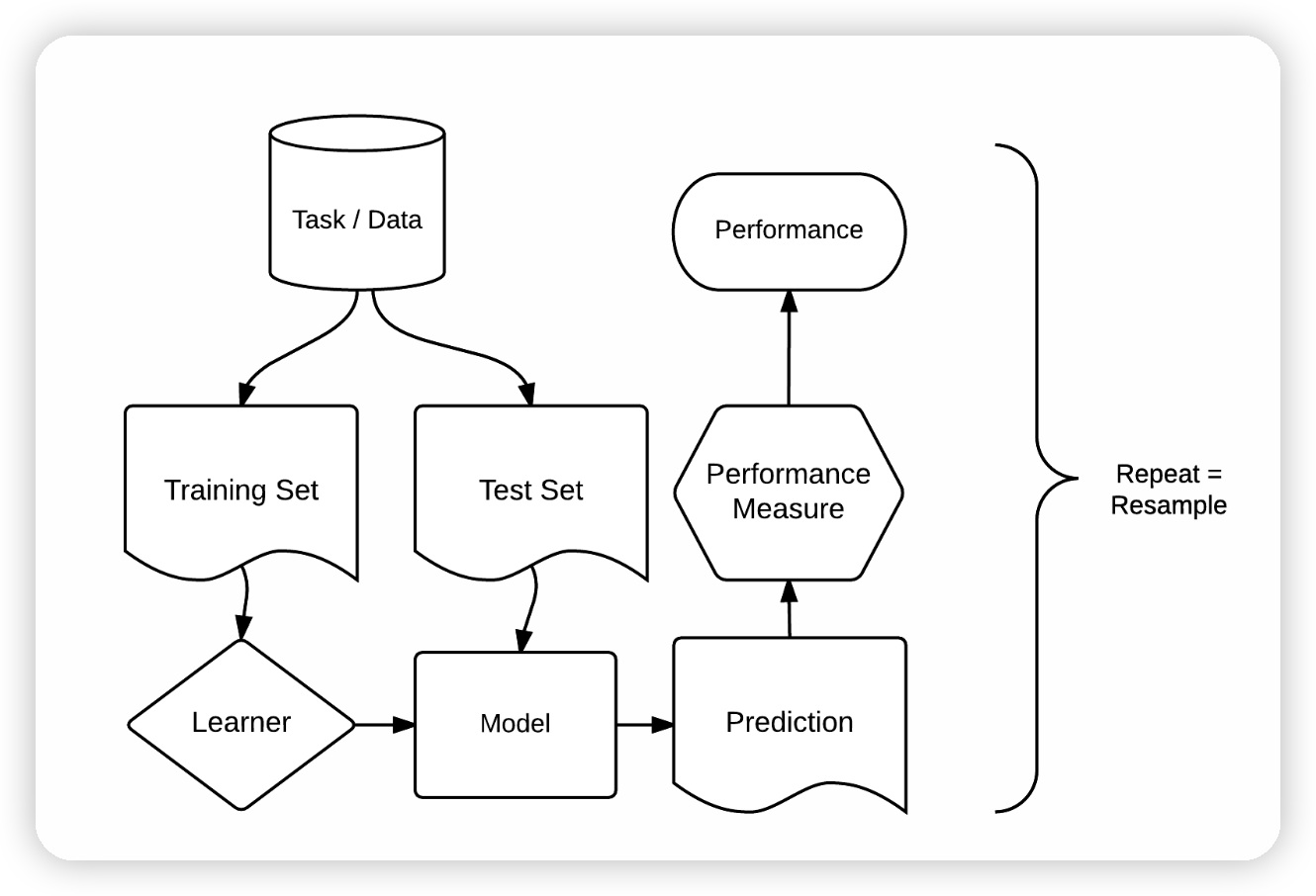
(ref:building-blocks)
mlr3 建模过程包含三个主要阶段。
首先,**任务(task)**指定了数据(包括响应变量和预测变量)和模型类型(如回归或分类)。
其次,学习器(learner) 定义了应用于创建的任务的特定学习算法。
第三,**重采样(resampling)**方法评估了模型的预测性能,即其泛化到新数据的能力。
广义线性模型
要在 mlr3中实现GLM,我们必须创建一个包含滑坡数据的任务(task)。由于响应是二元(两类变量)且具有空间维度,我们使用 mlr3spatiotempcv 包的TaskClassifST$new()创建一个分类任务[@schratz_mlr3spatiotempcv_2021,对于非空间任务,使用 mlr3::TaskClassif$new() 或对于回归任务使用mlr3::TaskRegr$new(),其他任务类型请参见 ?Task]。^[mlr3 生态系统大量使用 data.table 和 R6 类。尽管你可能在不了解 data.table 或 R6 的具体情况下使用 mlr3,但了解它们可能相当有帮助。要了解更多关于 data.table 的信息,请参考 https://rdatatable.gitlab.io/data.table/index.html。要了解更多关于 R6,我们推荐阅读《Advanced R》书的第14章 [@wickham_advanced_2019]。]
这些 Task*$new() 函数的第一个重要参数是 backend。backend 期望输入数据包括响应变量和预测变量。target 参数指示响应变量的名称(在我们的例子中是 lslpts),而 positive 决定响应变量的两个因子水平中哪一个表示滑坡起点(在我们的例子中是 TRUE)。lsl 数据集的所有其他变量将作为预测因子。对于空间交叉验证,我们需要提供一些额外的参数。coordinate_names 参数期望坐标列的名称(参见空间交叉验证章节和图3)。另外,我们应该指示使用的坐标参考系统(crs)并决定是否希望在建模中使用坐标作为预测因子(coords_as_features)。
1 | # create task |
注意,mlr3spatiotempcv::as_task_classif_st() 也接受一个 sf-对象作为 backend 参数的输入。在这种情况下,你可能只想额外指定 coords_as_features 参数。我们没有将 lsl 转换为一个 sf-对象,因为 TaskClassifST$new() 在背景中会将其转换回一个非空间的 data.table 对象。对于简短的数据探索,mlr3viz 包的 autoplot() 函数可能会很方便,因为它会绘制响应与所有预测因子的关系,以及所有预测因子之间的关系(未显示)。
1 | # plot response against each predictor |
创建了任务之后,我们需要选择一个学习器(learner),以确定要使用的统计学\index{statistical learning}方法。所有分类的学习器以 classif. 开头,所有回归的学习器以 regr. 开头(详见 ?Learner)。mlr3extralearners::list_mlr3learners() 列出了所有可用的学习器以及 mlr3 从哪个软件包中导入了它们(表 @ref(tab:lrns))。要了解能够对二元响应变量进行建模的学习器,我们可以运行:
1 | mlr3extralearners::list_mlr3learners( |
| Class | Name | Short name | Package |
|---|---|---|---|
| classif.adaboostm1 | ada Boosting M1 | adaboostm1 | RWeka |
| classif.binomial | Binomial Regression | binomial | stats |
| classif.featureless | Featureless classifier | featureless | mlr |
| classif.fnn | Fast k-Nearest Neighbour | fnn | FNN |
| classif.gausspr | Gaussian Processes | gausspr | kernlab |
| classif.IBk | k-Nearest Neighbours | ibk | RWeka |
这将产生所有能够处理两类问题(有或没有滑坡)的学习器。我们选择在传统建模节中使用的二项分类方法,该方法在 mlr3learners 中实现为 classif.log_reg。另外,我们需要指定 predict.type,它决定了预测的类型,prob 会得出滑坡发生概率在0到1之间的预测值(这对应于 predict.glm 中的 type = response)。
1 | learner = mlr3::lrn("classif.log_reg", predict_type = "prob") |
要访问学习器的帮助页面并找出它来自哪个包,我们可以运行:
1 | learner$help() |
1 | # performance estimation level |
请注意,这与节glm中用于GLM的重采样所用的代码完全相同;我们只是在这里重复它作为提醒。
到目前为止,这个过程与节glm中描述的过程相同。然而,下一步是新的:调整超参数。使用相同的数据进行性能评估和调优可能会导致过于乐观的结果[@cawley_overfitting_2010]。这可以通过使用嵌套的空间交叉验证(CV)来避免。
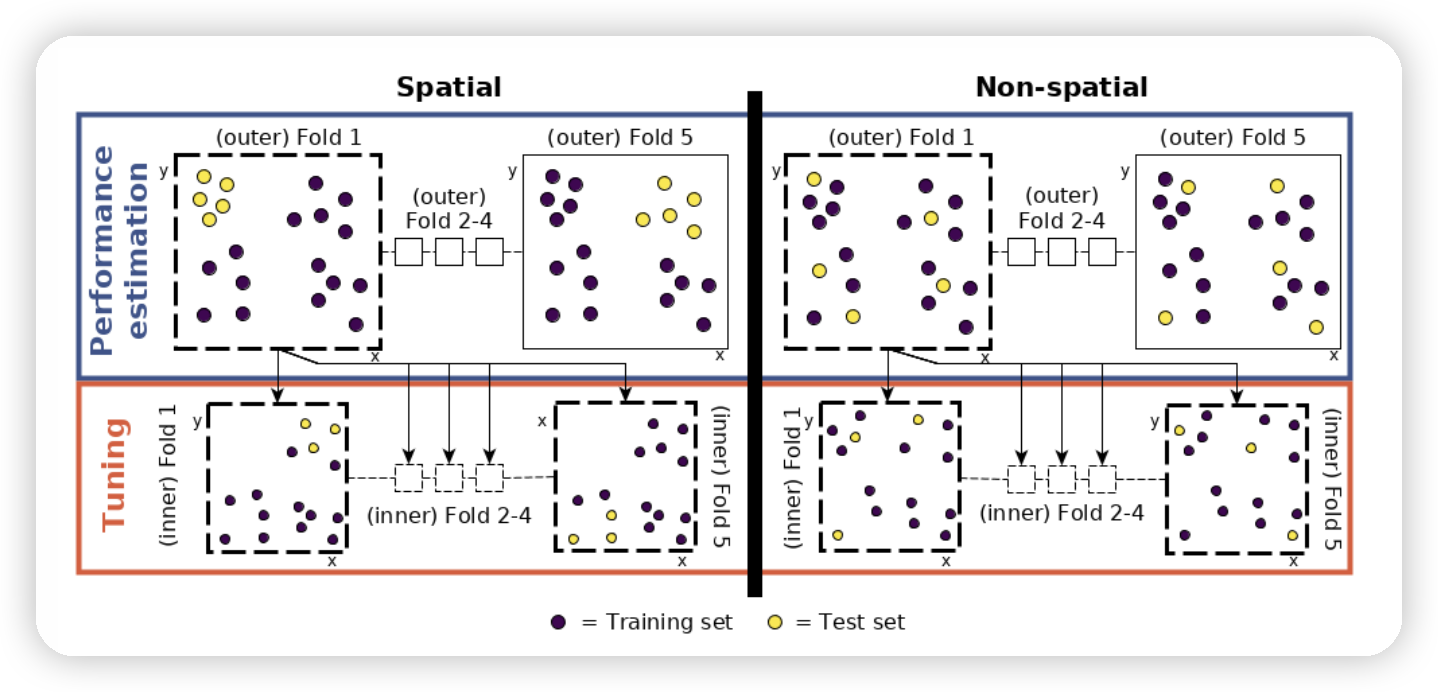
Schematic of hyperparameter tuning and performance estimation levels in CV. [Figure was taken from Schratz et al. (2019). Permission to reuse it was kindly granted.]
这意味着我们将每个折叠再次分成五个空间上不重叠的子折叠,这些子折叠用于确定最佳的超参数\index{hyperparameter}(下面代码块中的tune_level对象;见上图以获取视觉表示)。为了找到最优的超参数组合,我们在这些子折叠中分别拟合50个模型(下面代码块中的terminator对象),并为超参数C和Sigma随机选择值。C和Sigma的随机选择值还受到预定义调优空间(search_space对象)的额外限制。调优空间的范围是根据文献中推荐的值来选择的[@schratz_hyperparameter_2019]。
1 | # five spatially disjoint partitions |
下一步是根据所有定义超参数调优的特性,使用AutoTuner$new()来修改学习器lrn_ksvm。
1 | at_ksvm = mlr3tuning::AutoTuner$new( |
现在调优设置已完成,用于确定一个折叠的最佳超参数将拟合250个模型。重复这个过程针对每个折叠,我们最终得到125,000(250 * 5)个模型用于每次重复。重复100次意味着拟合总共125,000个模型以确定最佳超参数(见图)。这些将用于性能评估,这需要拟合另外500个模型(5个折叠 * 100次重复;参见图。
为了更清晰地描述性能评估处理链,让我们记录下我们给计算机的命令:
- 性能层次(图的左上部分)- 将数据集分成五个空间上不交叠的(外部)子折叠。
- 调优层次(图的左下部分)- 使用性能层次的第一个折叠,并再次将其空间上分成五个(内部)子折叠进行超参数调优。在这些内部子折叠中使用50个随机选定的超参数,即拟合250个模型。
- 性能估计 - 使用上一步(调优层次)中的最佳超参数组合,并将其应用于性能层次中的第一个外部折叠以估计性能(AUROC)。
- 重复步骤2和3,针对其余四个外部折叠。
- 重复步骤2至4,共100次。
超参数调优和性能估计的过程在计算上是非常密集的。为了减少模型运行时间,mlr3提供了使用future包进行并行化\index{parallelization}的可能性。由于我们即将进行嵌套交叉验证,我们可以决定是否希望并行化内部循环或外部循环(见图的左下部分)。由于前者将运行125,000个模型,而后者仅运行500个,很明显我们应该并行化内部循环。要设置内部循环的并行化,我们执行:
1 | library(future) |
确实,我们指示future包仅使用可用核心的一半而非全部(默认设置),这样做是为了在使用高性能计算集群的情况下允许其他可能的用户也能在同一个集群上工作。
现在,我们已经为执行嵌套空间交叉验证做好了准备。指定resample()参数的过程与使用GLM时完全相同,唯一的区别是store_models和encapsulate参数。将前者设置为TRUE将允许我们提取超参数调优结果,这在我们计划对调优进行后续分析时非常重要。后者确保即使其中一个模型出错,处理过程也会继续。这避免了由于一个失败的模型而导致整个过程停止,这在大规模模型运行中是非常需要的。一旦处理完成,可以查看失败的模型。处理完成后,最好使用future:::ClusterRegistry("stop")明确地停止并行化。最后,我们将输出对象(result)保存到磁盘,以防我们希望在另一个R会话中使用它。
在运行以下代码之前,请注意,由于它将执行包括125,500个模型在内的空间交叉验证,所以这是一个耗时的过程。在现代笔记本电脑上轻松运行半天也是可能的。需要注意的是,运行时间取决于多个方面:CPU速度、所选算法、所选核心数以及数据集。
1 | progressr::with_progress(expr = { |
如果你不想在本地运行代码,我们已经将 score_svm 保存在本书的GitHub仓库中。你可以按照以下方式加载它们:
1 | score = readRDS("extdata/12-bmr_score.rds") |
让我们看一下最终的AUROC:模型区分两个类别的能力。
1 | # final mean AUROC |
在这个特定情况下,似乎GLM(汇总的AUROC是 r score[resampling_id == "repeated_spcv_coords" & learner_id == "classif.log_reg", round(mean(classif.auc), 2)])比SVM略好一些。为了保证一个绝对公平的比较,还应确保两个模型使用完全相同的划分——这是我们在这里没有展示,但在背后默默使用的(更多信息请参见本书GitHub仓库中的code/12_cv.R)。为此,mlr3提供了benchmark_grid()和benchmark()函数[参见https://mlr3book.mlr-org.com/perf-eval-cmp.html#benchmarking,@becker_mlr3_2022]。我们将在练习中更详细地探讨这些函数。还请注意,在SVM的随机搜索中使用超过50次迭代可能会产生导致模型具有更好AUROC的超参数\index{hyperparameter} [@schratz_hyperparameter_2019]。另一方面,增加随机搜索迭代次数也会增加总模型数量,从而增加运行时间。
到目前为止,空间CV已被用于评估学习算法泛化到未见数据的能力。对于预测性制图目的,人们会在完整的数据集上调整超参数。这将在生态章中讨论。
结论
重采样方法是数据科学家工具箱中的一个重要组成部分[@james_introduction_2013]。本章使用交叉验证来评估各种模型的预测性能。具有空间坐标的观测值可能由于空间自相关而不是统计上独立的,这违反了交叉验证的一个基本假设。空间CV通过减少空间自相引入的偏见来解决这个问题。
mlr3软件包便于使用(空间)重采样技术,结合最受欢迎的统计学习技术,包括线性回归,如广义加性模型之类的半参数模型,以及如随机森林,SVMs和增强回归树[@bischl_mlr:_2016;@schratz_hyperparameter_2019]等机器学习技术。机器学习算法通常需要超参数输入,其中最优的“调整”可能需要数千次模型运行,这需要大量的计算资源,消耗大量时间、RAM和/或核心。mlr3通过启用并行化来解决这个问题。
总体而言,机器学习及其用于理解空间数据是一个大领域,本章提供了基础知识,但还有更多需要学习。我们推荐以下方向的资源:
- mlr3 book [@becker_mlr3_2022; https://mlr-org.github.io/mlr-tutorial/release/html/],特别是关于处理时空数据的章节
- 关于超参数\index{hyperparameter}调整的学术论文[@schratz_hyperparameter_2019]
- 关于如何使用mlr3spatiotempcv的学术论文[@schratz_mlr3spatiotempcv_2021]
- 在处理时空数据的情况下,应当在进行CV时考虑空间和时间自相关[@meyer_improving_2018]
练习
E1. 使用R-GIS桥梁(参见GIS软件桥梁章节),从通过terra::rast(system.file("raster/ta.tif", package = "spDataLarge"))$elev加载的elev数据集中计算以下地形属性:
- 坡度
- 平面曲率
- 轮廓曲率
- 流域面积
E2. 从相应的输出栅格中提取值到lsl数据框(通过data("lsl", package = "spDataLarge")),并添加名为slope、cplan、cprof、elev和log_carea的新变量。
E3. 结合GLM使用派生的地形属性栅格,制作一个与图12.2中显示的相似的空间预测地图。
运行data("study_mask", package = "spDataLarge")将学习区域的掩码附加上。
E4. 基于GLM学习器计算100次重复的5折非空间交叉验证和空间CV,并利用箱线图比较两种重采样策略的AUROC值。
提示:你需要指定一个非空间重采样策略。
另一个提示:你可能想借助mlr3::benchmark()和mlr3::benchmark_grid()(更多信息,请参考https://mlr3book.mlr-org.com/performance.html#benchmarking)一次性解决练习4至6。
在做此操作时,请记住计算可能需要很长时间,可能需要几天。
这当然取决于你的系统。
你拥有的RAM和核心越多,计算时间就会越短。
E5. 使用二次判别分析(QDA)对滑坡敏感性进行建模。
评估QDA的预测性能。
QDA和GLM的空间交叉验证平均AUROC值之间有什么区别?
E6. 不调整超参数运行SVM。
使用$\sigma$ = 1 和 C = 1的rbfdot核。
否则,在kernlab的ksvm()中不指定超参数将初始化自动的非空间超参数调整。