(3)属性操作
本文由SCY翻译自《Geocomputation with R》第三章
本章讲授如何基于属性来操作地理对象,例如矢量数据集中的公交站名和栅格数据集中像素的高程。对于矢量数据,意味着应用例如subsetting和aggregation方法(参见矢量属性提取子集和矢量属性聚合章节)。和创建属性移除空间信息章节演示了如何通过共享ID将数据连接到简单要素对象以及如何创建新变量。这些操作都有空间等效功能:例如,基于属性和空间对象的subsetting操作都可以使用R中的[运算符;您还可以使用spatial joins将两个地理数据集的属性进行连接。本章所培养的技能具有交叉传递性。空间数据操作章节将本章介绍的方法扩展到空间方面。
前提条件
- 本章要求安装并且连接以下包:
1 | library(sf) |
- 依赖于 spData 包,该包装载了本章代码示例所使用的数据集:
1 | library(spData) |
- 另外,如果您希望在栅格数据汇总章节中运行数据"整理"操作,请确保已安装了tidyr包,或者安装了其所属的tidyverse包。
引言
属性数据是与地理(几何)数据相关联的非空间信息。公共汽车站提供了一个简单的例子:除了名称之外,它的位置通常用经纬度坐标(几何数据)来表示。例如,位于伦敦Elephant & Castle / New Kent Road 站的坐标为:经度 -0.098和纬度 51.495,在空间数据类型章节描述的 sfc表示中可以表示为POINT (-0.098 51.495)。诸如点属性的name属性(使用 Simple Features 术语)之类的属性是本章的主题。
另一个示例是栅格数据中特定网格单元的海拔值(属性)。与矢量数据模型不同,栅格数据模型间接存储了网格单元的坐标,这意味着属性和空间信息之间的区分不太清晰。为了阐明这一观点,可以想象一下栅格矩阵中第3行第4列的像素点。其空间位置由其在矩阵中的索引确定:在x方向上从原点向右(通常是东方和地图上的右方)移动四个单元格,在y方向上从原点向下(通常是南方和向下)移动三个单元格。栅格的分辨率定义了每个x和y步的距离,这些距离在头部文件中指定。头部文件是栅格数据集的关键组成部分,它指定了像素与地理坐标的关系(另见空间数据操作章节)。
本章讲授如何基于属性来操作地理对象,例如矢量数据集中的公交站名和栅格数据集中像素的高程。对于矢量数据,意味着应用例如subsetting和aggregation方法(参见矢量属性提取子集和矢量属性聚合章节。)和创建属性移除空间信息章节演示了如何通过共享ID将数据连接到简单要素对象以及如何创建新变量。这些操作都有空间等效功能:例如,基于属性和空间对象的subsetting操作都可以使用R中的[运算符;您还可以使用spatial joins将两个地理数据集的属性进行连接。本章所培养的技能具有交叉传递性。空间数据操作章节将本章介绍的方法扩展到空间方面。
在下一节深入探讨各种类型的矢量属性操作后,栅格数据操作章节介绍了栅格属性数据操作,演示了如何创建包含连续和分类属性的栅格图层,并从一个或多个图层中提取单元格的值(栅格子集)。栅格数据汇总章节提供了全局栅格操作的概述,这些操作可以用于总结整个栅格数据集。
矢量数据操作
地理矢量数据集在R中得到了很好的支持,这得益于sf类的出现,它是基于R的data.frame进行扩展的。与数据框类似,sf对象每列都有一个属性变量(例如"name"),每行代表一个观测值或feature(例如每个公交车站)。与基本数据框不同的是,sf对象具有一个几何列,其类型为sfc,每个行可以包含多个地理实体(单个和"多"点,线,多边形要素)。空间类中进行了描述,演示了plot()和Summary()等通用方法是如何处理sf对象的。sf还提供了通用方法,允许sf对象像常规数据框一样运行,如打印类的方法所示:
1 | methods(class = "sf") |
1 | #> [1] [ [[<- $<- aggregate |
其中许多函数(aggregate(),cbind(),merge(),rbind()和[)用于操作数据框。例如,rbind()会将数据框的行"一上一下"连接在一起。$
<-可以创建新的列。sf 对象的一个重要特征是它们以相同的方式将空间数据和非空间数据存储为data.frame中的列。
📌对象的几何列通常称为
geometry或geom,但可以使用任何名称。例
如,下面的命令创建了一个名为g的几何列:st_sf(data.frame(n = world$name_long), g = world$geom)这使得从空间数据库导入的几何图形具有多种名称,如wkb_geometry和The_geom。
sf对象对于数据框可以扩展tidyverse类,tbl_df和tbl。因此,无论您使用基础R还是tidyverse函数进行数据分析,sf都可以释放R数据分析能力对地理数据的全部威力。
sf对象还可以与高性能数据处理软件包data.table一起使用,尽管文献中有记载说明,它与sf对象不完全兼容,Rdatatable/data.table#2273。在使用这些功能之前,回顾怎样探索矢量数据对象的基本属性。让我们开始使用基本R函数来了解从 spData 软件包中的world数据集:
1 | class(world) |
world含有十个非地理列(以及一个几何列表列),共有近200行代表各个世界国家。函数st_drop_geometry()可保留仅为sf对象的属性数据,也就是删除其几何学属性:
1 | world_df = st_drop_geometry(world) |
在使用属性数据之前,删除几何列可能会很有用;当数据处理过程仅涉及属性数据时,处理速度可以更快,并且不一定总需要几何列。然而,在大多数情况下,保留几何列是有意义的,解释为什么几何列具有"粘性"(大多数属性操作之后仍然存在,除非特别删除。)。在sf对象上进行非空间数据操作仅在适当时更改对象的几何结构(例如,在聚合后消除相邻多边形之间的边界)。掌握地理属性数据操作技能意味着掌握操作数据框的技能。
对于许多应用程序来说,tidyverse中的dplyr 包为处理数据框提供了有效的方法。与其前身sp相比,sf具有tidyverse兼容性的优势,但需要避免一些陷阱(详情请参见 geocompx.org 上的补充tidyverse-pitfalls文献)。
矢量属性提取子集
基础R的子集提取方法包括[和subset()。在dplyr中,子集提取数据的关键函数是filter()和slice()用于子集提取行,而select()用于子集提取列。两
种方法都可以保持 sf对象中属性数据的空间组件不变。然而,使用运算符$或dplyr函数pull()提取单个属性列作为向量会导致几何数据的丢失,我们将在后文中进一步阐述。本
节重点关注如何对sf数据框进行子集提取,如果进一步了解如何对向量和非地理数据框进行子集提取,建议参考《An Introduction to R》第2.7 节以及《Advanced R Programming》第4章。
[操作符可以对行和列提取子集。方括号直接放在数据框对象名称之后,里面的索引指定要保留的元素。命令object[i, j]意味着:返回由i表示的行和由j表示的列,其中i和j通常包含整数或TRUE和FALSE(索引也可以是字符串,表示行或列名称)。例如,object[5, 1:3]意味着:返回包含第5行和第1到第3列的数据,结果应该是一个只有1行和3列的数据框,如果是sf对象,则还要包含第4个几何列。留下i或j为空会返回所有的行或列,因此world[1:5, ]返回前5行和所有11列。下面的示例演示了使用基本R进行子集提取的方法。猜测每个命令返回的sf数据框的行数和列数,并在自己的计算机上检查结果(更多练习请参见本章末尾):
1 | world[1:6, ] # 按位置提取行 |
下面的代码块演示了使用logical向量进行子集提取的实用性。这就创造了一个新的对象,small_countries,包括面积小于 10,000 $km^2$的国家:
1 | i_small = world$area_km2 < 10000 |
中间的i_small(表示小国家的索引的缩写)是一个逻辑向量,可用于按表面积对世界上最小的七个国家提取子集。更简洁的命令省略中间对象,生成相同的结果:
1 | small_countries = world[world$area_km2 < 10000, ] |
基础R函数subset()提供了另外一种方式:
1 | small_countries = subset(world, area_km2 < 10000) |
基础的R函数成熟、稳定且广泛使用,使它们成为一种非常可靠的选择,特别是在强调重现性和可靠性的情况下。dplyr 函数使得"tidy"的工作流成为可能,其中一些人(包括本书的作者)在交互式数据分析中发现这些函数直观且富有成效,特别与RStudio等代码编辑器相结合,可以实现列名的auto-completion。下面演示了使用dplyr函数进行子集提取中的关键函数,包括sf数据框架。
select()按照名称和位置选择列。例如,你可以利用下面的命令只选择name_long和pop两列:
1 | world1 = select(world, name_long, pop) |
注意:与基础R中的等效命令一样,(world[, c("name_long", "pop")]), “粘性” geom列保留。select()还允许在:操作符的帮助下选择一系列列变量:
1 | # name_long 和 pop (包括)之间的所有列 |
用-操作符去除特定的列:
1 | # 除了 subregion 和 area_km2 (包括)之外的所有列 |
new_name = old_name语法可以同时提取子集和重命名列变量:
1 | world4 = select(world, name_long, population = pop) |
值得注意的是:上面的命令比基础R等价的命令更简洁,基础R等价的命令需要两行代码:
1 | world5 = world[, c("name_long", "pop")] # 通过名称提取子列 |
select()还可以使用’helper functions’ 进行更高级的自己提取操作,包括contains(),starts_with()和num_range()(用?select产看帮助页面获取更多细节)。
大部分 dplyr 函数返回数据框,但是你可以用pull()单独提取一列作为向量。
使用列表提取子集操作符$和[[ ,可以在基础 R 中得到相同的结果,以下三个命令返回相同的数值向量:
1 | # 结果返回为向量 |
slice()是行选择工具等同于 select()。例如,下面的代码块选择了1到6行:
1 | slice(world, 1:6) |
filter()是dplyr等价于基础 R 的subset()函数。它只保留符合给定标准的行,例如,只保留面积低于某一阈值或平均预期寿命高的国家,如下例所示:
1 | world7 = filter(world, area_km2 < 10000) # 面积小的国家 |
比较运算符的标准集合可以在filter()函数中使用,如表所示:
| Symbol | Name |
|---|---|
== |
Equal to |
!= |
Not equal to |
>, < |
Greater/Less than |
>=, <= |
Greater/Less than or equal |
&,` |
,!` |
: Comparison operators that return Booleans (TRUE/FALSE).
管道连接命令
使用dplyr函数的工作流的关键是’pipe’操作符%>%(或者自R 4.1.0以来的内置管道|>),名称取自Unix管道 |。管道启用表达式代码:前一个函数的输出成为下一个函数的第一个参数,从而启用连接。如下所示,其中只有来自亚洲的国家从world数据集中筛选,接下来对象是按列(name_long和continent)和前5行(结果未显示)分列的子集。
1 | world7 = world |> |
上面的代码块显示了管道操作符如何允许以明确的顺序编写命令:从上到下(逐行)和从左到右运行。管道操作的另一种替代方法是嵌套函数调用,这种方法更难理解:
1 | world8 = slice( |
另一种选择是将操作分为多个自包含行,特别是在开发新的 R 程序包时推荐使用此方法,这种方法的优点是可以通过具有不同名称的中间结果进行保存以便后续调试(但缺点是冗长,如果进行交互式分析时还会使全局环境凌乱):
1 | world9_filtered = filter(world, continent == "Asia") |
每种方法都有优缺点,其重要性取决于您的编程风格和应用程序。对于交互式数据分析(本章的重点),我们发现管道操作快速而直观,特别是与RStudio/VSCode快捷方式相结合时,可以创建管道并自动完成变量名。
矢量属性聚合
聚合涉及使用一个或多个"分组变量"对数据进行汇总,通常是从要进行聚合的数据框的列中选择的(地理聚合在下一章中介绍)。属性聚合的一个例子是根据以国家为单位的数据(每个国家一行)计算每个大洲的人口数量。world数据集包含了必要的要素:pop和continent列分别代表人口和分组变量。目的是找到每个大洲的国家人口总和(sum()),从而得到一个较小的数据框(聚合是一种数据缩减的形式,对于处理大型数据集时,聚合是有用的前期步骤)。可以使用基本R函数aggregate()来完成此操作,步骤如下所示:
1 | world_agg1 = aggregate(pop ~ continent, FUN = sum, data = world, |
结果是一个6行的非空间数据框,每一行代表一个大洲,两列分别报告了每个大洲的名称和人口(参见表),显示前三个人口最多的大洲的结果)。
aggregate()是一个泛函数,这意味着它的行为取决于它的输入。sf提供了aggregate.sf()方法,当x是一个sf对象且提供了一个by参数时,它会自动激活:
1 | world_agg2 = aggregate(world["pop"], list(world$continent), FUN = sum, |
由此产生的world_agg2对象是一个包含8个特征的空间对象,这些特征代表世界的大陆(和开放的海洋)。
group_by() |> summarize()是 dplyr 中与aggregate()等效的函数,其中在group_by()函数中提供的变量名称指定了分组变量,而对要进行汇总的信息则是通过传递给 summarize()函数来指定的,如下所示:
1 | world_agg3 = world |> |
这种方法可能看起来更复杂,但它具有以下好处:灵活性、可读性以及对新列名称的控制。下面的命令示例展示了这种灵活性,它不仅计算了人口数量,还计算了每个大洲的面积和国家数量:
1 | world_agg4 = world |> |
在前一个代码块中,Pop、Area和N是结果中的列名,sum()和n()是聚合函数。这些聚合函数返回的sf对象具有以大洲表示的行和包含每个陆地和相关岛屿的多个多边形的几何信息(这得益于几何操作union,如几何合并节所述)。
让我们结合目前已经学习到的dplyr函数知识,通过将多个命令链接起来以总结全球各大洲的属性数据。以下命令使用mutate()函数计算人口密度,使用dplyr::arrange()函数按国家数量排列大洲,使用dplyr::slice_max()函数保留人口最多的3个洲,并呈现结果简单表格:
1 | world_agg5 = world |> |
| continent | Pop | Area | N | Density |
|---|---|---|---|---|
| Africa | 1154946633 | 29946198 | 51 | 39 |
| Asia | 4311408059 | 31252459 | 47 | 138 |
| Europe | 669036256 | 23065219 | 39 | 29 |
: The top 3 most populous continents ordered by number of countries.
更多细节可在帮助页面中查看(可通过
?summarize和vignette(package = "dplyr")访问)以及R for Data Science第5章。
矢量属性连接
在数据准备中,合并不同来源的数据是一种常见的任务。连接(Join)函数通过基于共享的"key"变量来合并表格。dplyr有多个连接函数,包括left_join()和inner_join(),详见vignette("two-table")以获取完整列表。这些函数名称遵循数据库语言SQL中使用的惯例。本部分重点讨论将非空间数据集与sf对象连接的过程。dplyr连接函数在数据框和sf对象上的操作相同,唯一重要的区别是geometry列表列。数据合并的结果可以是sf或data.frame对象。在空间数据中,最常见的属性合并类型是将sf对象作为第一个参数,并从作为第二个参数指定的data.frame中添加列。
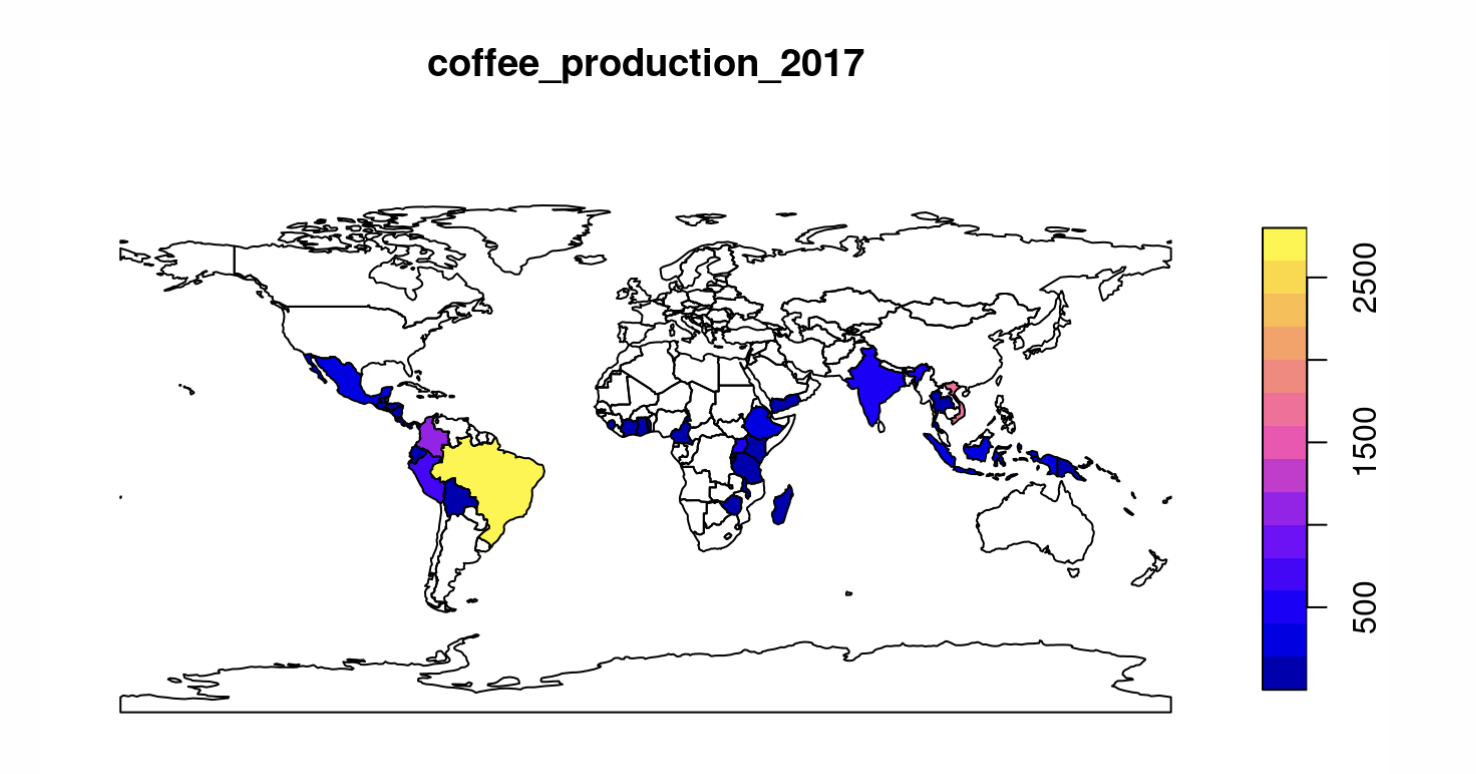
为了展示连接,我们将把咖啡生产数据和world数据集合并。咖啡数据存储在一个名为coffee_data的数据框中,来自spData包(详情请参见?coffee_data)。它有3列:name_long列记录主要咖啡生产国家的名称,coffee_production_2016和coffee_production_2017列分别包含每年以60公斤袋为单位的咖啡生产估值。'left join’保留第一个数据集,将world与coffee_data合并:
1 | world_coffee = left_join(world, coffee_data) |
由于输入数据集共享’key variable’(name_long),因此连接操作可以在不使用by参数的情况下完成(有关详细信息,请参见?left_join)。结果是一个与原始world对象相同的sf对象,但具有两个新变量(列索引为11和12)的咖啡产量。这可以绘制成地图,如下🖼️ 图片的plot()函数所示:
1 | names(world_coffee) |
为了使连接生效,两个数据集都必须提供’key variable’ 。默认情况下,dplyr会使用所有名称匹配的变量。在这种情况下,world_coffee和world两个对象都包含一个名为name_long的变量,这解释了信息Joining with by = join_by(name_long)。在大多数名称不同的情况下,您有两个选项:
- 重命名某个对象中的key variable,使其与其他对象匹配。
- 使用
by参数指明连接变量。
后一种方法在coffee_data的重命名版本中演示如下:
1 | coffee_renamed = rename(coffee_data, nm = name_long) |
请注意,在原始对象中保留名称,意味着world_coffee和新对象world_coffee2是相同的。结果的另一个特点是具有与原始数据集相同的行数。尽管coffee_data中仅有47行数据,但world_coffee和world_coffee2中保留了所有177个国家记录:在原始数据集中没有匹配的行会被赋予新咖啡生产变量的NA值。如果我们只想保留具有键变量匹配的国家怎么办?在
这种情况下,可以使用内连接:
1 | world_coffee_inner = inner_join(world, coffee_data) |
inner_join()的结果只有45行,而coffee_data中有47行。剩下的行发生了什么?我们可以使用setdiff()函数来识别未匹配行,如下所示:
1 | setdiff(coffee_data$name_long, world$name_long) |
结果显示,Others占据了world数据集中不存在的一行,而Democratic Republic of the Congo的名称占据了另一行: 名称缩写,导致连接错误。下面的命令使用stringr包中的字符串匹配(regex)函数来确认Congo, Dem. Rep. of应为:
1 | drc = stringr::str_subset(world$name_long, "Dem*.+Congo") |
为了解决这个问题,我们将创建一个新版本的coffee_data并更新名称。inner_join()更新后的数据框返回一个包含所有46个咖啡生产国的结果:
1 | coffee_data$name_long[grepl("Congo,", coffee_data$name_long)] = drc |
也可以从另一个方向连接:从非空间数据集开始,并从简单要素对象中添加变量。下面演示了这一点,从coffee_data对象开始,并从原始world数据集中添加变量。与前面的连接相比,结果不是另一个简单要素对象,而是一个tidyverse数据框格式的tibble。连接的输出往往与其第一个参数相匹配:
1 | coffee_world = left_join(coffee_data, world) |
📌在大多数情况下,几何列只在
sf对象中有用。
只有当R"知道"它是由如sf等空间包定义的空间对象时,几何列才能用于创建地图和空间操作。
幸运的是,具有几何列表列(如coffee_world)的非空间数据框可以如下方式强制转换为sf对象:st_as_sf(coffee_world)。
本节涵盖了大部分的连接使用情况。如需更多信息,我们建议阅读Relational data章节,本书附带的geocompkg包中的join vignette,以及描述data.table和其他包中的连接方法的文档。空间连接将在下一章空间连接中讲述。
创建属性移除空间信息
通常,我们想要根据已有的列创建新的列。例如,我们想要计算每个国家的人口密度。为此,我们需要将一个人口列(这里是pop)除以一个面积列(这里是area_km2),其中单位面积为平方千米。使用基础R,我们可以输入:
1 | world_new = world # 不要覆盖原始数据 |
另外,我们还可以使用dplyr函数-mutate()或transmute()。mutate()在sf对象的倒数第二个位置添加新的列(最后一个位置是保留给几何图形的):
1 | world_new2 = world |> |
mutate()和transmute()的区别在于transmute()会删除所有其他已存在的列(除了sticky geometry列)。
unite()函数来自tidyr包(该包提供了许多重塑数据集的有用函数,包括pivot_longer()),unite()函数将现有的列拼接在一起。例如我们想要将continent和region_un列合并成一个名为con_reg的新列。另外,我们可以定义一个分隔符(这里是冒号:),用于定义输入列的值应该如何拼接,并且确定是否删除原始列(这里是TRUE)。
1 | world_unite = world |> |
生成的sf对象有一个名为con_reg的新列,代表每个国家的大陆和地区,例如,South America:Americas代表阿根廷和其他南美洲国家。tidyr 的separate()函数的作用与unite()相反: 它使用正则表达式或字符位置将一列拆分为多列。
1 | world_separate = world_unite |> |
dplyr函数rename()和基础 R 中的setNames()函数用于重命名列变量。rename()函数用新名称代替就名称。例如,下面的命令重命名name_long列为name:
1 | world |> |
setNames()函数一次性改变全部列名,并需要一个与各列匹配的字符向量。下面的示例说明了这一点,输出相同的world对象,但列名变得非常简单:
1 | new_names = c("i", "n", "c", "r", "s", "t", "a", "p", "l", "gP", "geom") |
每个属性数据操作都保留简单要素的几何特征。有时候去除几何特征是有意义的。例如,为了加快聚合速度。请使用st_drop_geometry()进行操作,而不是手动使用诸如select(world, -geom)等命令,如下所示。
st_geometry(world_st) = NULL 也可以用来从 world 中移除几何信息,但它会覆盖原始对象。
1 | world_data = world |> st_drop_geometry() |
栅格数据操作
与简单要素基础下的矢量数据模型相反(它将点、线和多边形表示为空间中的离散实体),栅格数据表示连续表面。本节将展示如何从头开始创建栅格对象,并基于terra介绍章节进行构建。由于它们独特的结构,对栅格数据集的子集提取和其他操作以不同的方式进行,在栅格数据提取子集章节中展示。
以下代码重新创建了在栅格类节使用的栅格数据集,其结果在🖼️ 图片中展示。这
展示了rast()函数如何工作来创建一个名为elev的示例栅格(表示高程)的示例。
1 | elev = rast(nrows = 6, ncols = 6, |

结果是一个具有6行和6列的栅格对象(由nrow和ncol参数指定),以及x和y方向上的最小和最大空间范围(xmin,xmax,ymin,ymax)。vals参数设置每个单元格包含的值:在这种情况下,是从1到36的数值数据。Raster对象还可以包含在R中logical或factor类变量形式表示的分类值。以下代码创建了图所示的栅格数据集:
1 | grain_order = c("clay", "silt", "sand") |
栅格对象将相应的查找表或"栅格属性表"(RAT)存储为数据框列表,可以使用cats(grain)查看(有关更多信息,请参见?cats())。该列表的每个元素都是一个栅格层。还可以使用levels()函数检索和添加新的或替换现有的因子级别:
1 | levels(grain) = data.frame(value = c(0, 1, 2), wetness = c("wet", "moist", "dry")) |
📌分类栅格对象还可以使用颜色表存储与每个值相关联的颜色信息。
颜色表是一个数据框,有三个(红色、绿色、蓝色)或四个(Alpha)列,其中每一行与一个值相关联。
在terra中,可以使用coltab()函数查看或设置颜色表(请参阅?coltab)。
需要注意的是,将带有颜色表的栅格对象保存到文件(例如GeoTIFF)中也会保存颜色信息。
栅格数据提取子集
用基础R中的[操作符提取栅格数据子集,改运算符接受多种输入:
- 行-列索引
- 单元格 IDs
- 坐标系(见空间栅格子集提取节)
- 其他的空间对象(见空间栅格子集提取节)
在这里,我们只展示前两个选项,因为它们可以被视为非空间操作。如果我们需要一个空间对象来对另一个对象进行子集提取,或者输出是一个空间对象,我们将其称为空间子集操作。因
此,后两个选项将在下一章中进行展示(见空间栅格子集提取节)。
前两个子集操作选项在下面的命令中进行了演示------两者都返回栅格对象elev中左上角像素的值(结果未显示):
1 | # row 1, column 1 |
多层栅格对象的子集提取将返回每层的单元格值。例如,two_layers = c(grain, elev);two_layers[1]返回一个包含一行两列的数据框架——每层一列。若
要提取所有值或完整行,还可以使用values()。
可以通过与子集提取操作一起覆盖现有值来修改单元格值。例如,下面的代码块将elev的左上单元格设置为0(结果未显示):
1 | elev[1, 1] = 0 |
留空方括号是使用values()检索栅格的所有值的快捷方式,通过此方式也可以修改多个单元格:
替换多层栅格的值可以使用矩阵,其列数与层数相同,行数与可替换单元格数相同(结果未显示):
1 | two_layers = c(grain, elev) |
栅格数据汇总
terra包含提取整个栅格数据描述性统计信息的功能。通过输入栅格对象的名称并将其打印到控制台,可以返回栅格的最小值和最大值。summary()提供了常见的描述性统计量——最小值、最大值、四分位数以及连续型栅格NA的数量,以及分类型栅格中每个类别的单元格数量。进一步的总结操作,例如标准偏差(见下文)或自定义总结统计量,可以通过global()计算得出。
1 | global(elev, sd) |
如果您向
summary()和global()函数提供一个多层栅格对象,它们将分别总结每一个层次,可以通过运行以下命令进行演示:summary(c(elev, grain))。
此外,freq()函数允许获取分类值的频率表。栅格值统计可以以多种方式进行可视化。特定的函数,如boxplot()、density()、hist()和pairs()也适用于栅格对象,如下方命令创建的直方图所示(未显示):
1 | hist(elev) |
如果所需的可视化函数无法与栅格对象一起使用,可以使用values()函数提取要绘制的栅格数据(参见栅格数据提取子集节)。
描述性栅格统计属于所谓的全局栅格操作。这些以及其他典型的栅格处理操作是地图代数方案的一部分,将在下一章(地图代数节)中介绍。
📌一些函数名在包之间发生了冲突(例如,
extract()函数在terra和tidyr包中都有)。
除了不通过引用函数来加载包(例如,tidyr::extract()),还有一种避免函数名冲突的方法是使用detach()取消加载引起问题的包。
例如,下面的命令可以卸载terra包(这也可以在 RStudio的默认右下角窗格中的package选项卡中完成):detach("package:terra", unload = TRUE, force = TRUE)。在
使用force参数时,即使其他包依赖于该包,也可以确保分离该包。
然而,这可能会导致依赖于已分离包的包受到限制的可用性,因此不建议使用该参数。
练习
对于这些练习,我们将使用spData包中的us_states和us_states_df数据集。你必须已经加载了包,以及在属性操作章节中使用的其他包(sf, dplyr, terra),通过如library(spData)这样的命令,在尝试这些练习之前:
1 | library(sf) |
us_states是一个空间对象(类为sf),包含了美国连续州的几何形状和一些属性(包括名字、区域、面积和人口)。us_states_df是一个数据框架(类为data.frame),包含了美国各州的名称和额外变量(包括 2010 年和 2015 年的中位数收入和贫困水平),包括阿拉斯加、夏威夷和波多黎各。数据来自美国人口普查局,并在?us_states和?us_states_df中有文档记录。
E1.
创建一个叫做us_states_name的新对象,它只包含来自us_states对象的NAME列,使用基础 R ([) 或 tidyverse (select()) 语法。新对象的类是什么,是什么使它具有地理特征?
E2.
从us_states对象中选择包含人口数据的列。使用不同的命令获得相同的结果(奖励:尝试找到三种获得相同结果的方法)。提示:尝试使用辅助函数,如dplyr中的contains或matches(参见?contains)。
E3.
找到所有具有以下特征的州(找到并绘制它们):
- 属于中西部区域。
- 属于西部区域,面积低于 250,000 平方千米并且在 2015 年人口超过 5,000,000(提示:你可能需要使用
units::set_units()或as.numeric()函数)。 - 属于南部区域,面积大于 150,000 平方千米或 2015 年总人口超过 7,000,000。
E4.
在us_states数据集中,2015 年的总人口是多少?2015 年的最小和最大总人口是多少?
E5.
每个区域有多少个州?
E6.
2015 年每个区域的最小和最大总人口是多少?2015 年每个区域的总人口是多少?
E7.
从us_states_df添加变量到us_states,并创建一个叫做us_states_stats的新对象。你使用了什么函数,为什么?在这两个数据集中哪个变量是键?新对象的类是什么?
E8.
us_states_df比us_states多两行。你怎么找到它们?(提示:尝试使用dplyr::anti_join()函数)
E9.
2015 年每个州的人口密度是多少?2010 年每个州的人口密度是多少?
E10.
2010 年和 2015 年每个州的人口密度变化了多少?计算百分比变化并将它们映射出来。
E11.
将us_states中的列名更改为小写。(提示:辅助函数 - tolower()和colnames()可能会有帮助)
E12.
使用us_states和us_states_df创建一个叫做us_states_sel的新对象。新对象应该只有两个变量 - median_income_15和geometry。将median_income_15列的名称更改为Income。
E13.
计算 2010 年和 2015 年每个州贫困线以下居民数量的变化。(提示:参见?us_states_df了解贫困水平列的文档)奖励:计算每个州贫困线以下居民的百分比变化。
E14.
2015 年每个区域的最小、平均和最大州贫困线以下人口数量是多少?奖励:哪个区域贫困线以下人口增加最多?
E15.
从头开始创建一个具有九行和九列的栅格,分辨率为 0.5 十进制度(WGS84)。用随机数填充它。提取四个角单元格的值。
E16.
我们示例栅格grain最常见的类是什么?
E17.
绘制spDataLarge包中dem.tif文件的直方图和箱线图(system.file("raster/dem.tif", package = "spDataLarge"))。